Beim Navigieren im Web können sowohl Benutzer als auch Suchmaschinen auf verschiedene HTTP-Fehlercodes stoßen, die auf Zugriffsprobleme hinweisen. Unter diesen sind die Fehlercodes 401 "Nicht autorisiert" und 403 "Verboten" zwei der häufigsten.
Diese HTTP-Antwortstatuscodes werden von Servern gesendet, um anzuzeigen, ob eine Anfrage "erfolgreich" war oder "fehlgeschlagen" ist.
Aber was ist der wirkliche Unterschied zwischen den Fehlercodes 401 und 403? In diesem Blogbeitrag werden wir es aufschlüsseln und erklären, wie diese Fehler Ihr SEO beeinflussen können.
Was ist der Unterschied zwischen den Fehlercodes 401 und 403?
"Fehlercodes" 401 und 403 [zeigen] beide [Probleme] beim Zugriff auf eine Ressource auf einem Server an.
Hier sind die wichtigsten Unterschiede zwischen 401- und 403-Serverantworten:
Authentifizierung
Ein 401-Fehler tritt auf, wenn ein unbefugter Zugriffsversuch auf den Server erfolgt.
Im Gegensatz dazu tritt ein 403 Forbidden-Fehler auf, wenn der Server den Benutzer erkennt, aber feststellt, dass er nicht die erforderlichen Berechtigungen hat.
Mit anderen Worten, ein 403-Statuscode bedeutet, dass der Benutzer gültige Anmeldeinformationen bereitgestellt hat, aber dennoch nicht die entsprechenden Berechtigungen hat, um den Inhalt anzuzeigen.
Wie man [löst]
Für einen 401-Statuscode wird das Problem gelöst, indem sichergestellt wird, dass der Benutzer gültige Anmeldedaten bereitstellt, wie z.B. einen korrekten Benutzernamen und ein korrektes Passwort.
Im Gegensatz dazu erfordert ein 403-Statuscode einen anderen Ansatz, da der Benutzer bereits korrekte Anmeldedaten bereitgestellt hat. Sie können das Problem lösen, indem Sie die Berechtigungen des Benutzers überprüfen und anpassen oder serverseitige Einschränkungen beheben, die den Zugriff auf die Ressource blockieren.
Komplexität
Der HTTP 401 [Unauthorized] Fehler ist weniger komplex, da er sich um das Versagen dreht, [Authentifizierungsprotokolle] wie die grundlegende oder bearer token [Authentifizierung] zu erfüllen.
Alternativ ist der HTTP 403 "Verboten" Fehler technisch komplexer. Es erfordert die Bewertung von "Zugriffskontrolllisten", "rollenbasierter Zugriffskontrolle" oder "discretionary access control".
Hier erzwingt der Server "richtlinienbasierte" Einschränkungen und verweigert den Zugriff aufgrund unzureichender Berechtigungen, selbst wenn die richtigen Authentifizierungs-Header bereitgestellt werden.
Was ist ein 401-Fehlercode?
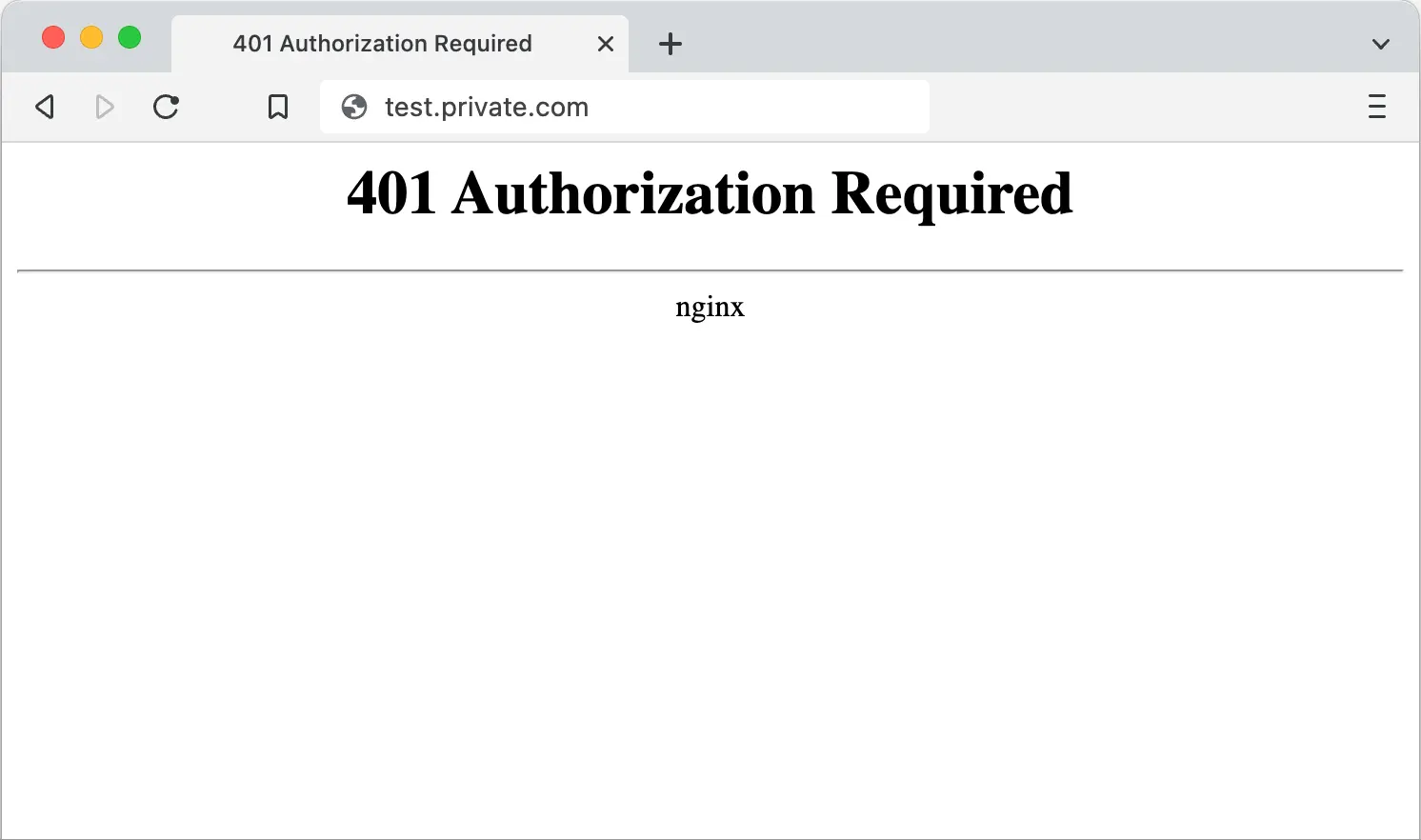
Der HTTP-Statuscode 401 bedeutet, dass die Clientanfrage nicht "authentifiziert" ist. Der Server kann die Identität des Clients aufgrund fehlender gültiger "Anmeldeinformationen" nicht überprüfen.
401-Fehler wird aus folgenden Gründen ausgelöst:
- Keine Anmeldedaten bereitgestellt: Wenn ein Benutzer versucht, auf eine Datei zuzugreifen, aber Authentifizierungsdaten fehlen. Manchmal versäumen es Benutzer, ein ordnungsgemäß signiertes Token bereitzustellen, was dazu führt, dass der Zugriff verweigert wird.
- Ungültige Anmeldedaten: Probleme beim [Anmelden] können auch aufgrund von Serverfehlkonfiguration oder falschen Datenbankverbindungen auftreten. In diesem Fall gibt der Benutzer Anmeldedaten ein, aber sie sind [falsch], oder die TLS-Zertifizierung ist nicht richtig konfiguriert.
- Abgelaufene Anmeldeinformationen: In vielen Fällen laufen die zwischengespeicherten Anmeldeinformationen ab und erfordern eine erneute Authentifizierung. Einige Fehlkonfigurationen könnten auch zu endlosen Schleifen führen, bei denen die Anmeldeseite weiterhin geladen wird.
- Unzureichende Berechtigungen: Der Benutzer ist authentifiziert, [hat] aber nicht die erforderlichen Berechtigungen, um die gewünschte Datei zu erreichen.
- Fehlender Autorisierungs-Header: Der Benutzer versäumt es, den erforderlichen Autorisierungs-Header in die Anfrage einzufügen.
- Probleme mit Cookies: Wenn ein Sitzungs- oder Authentifizierungs-Cookie fehlt, veraltet oder falsch ist, gibt der Server einen 401-Statuscode aus. Dies erfordert, dass der Benutzer sich erneut anmeldet.
Die Antwort des Servers enthält einen WWW-Authenticate-Header, der die erforderliche Authentifizierungsmethode angibt (z. B. "Basic", "Digest", "Bearer"). Dieser Header fordert den Client auf, die erforderlichen Anmeldeinformationen bereitzustellen.
Wenn die Anmeldedaten "ungültig" sind, gibt der Server einen 401-Status zurück, bis "gültige" Anmeldedaten bereitgestellt werden.
Was ist ein 403-Fehlercode?
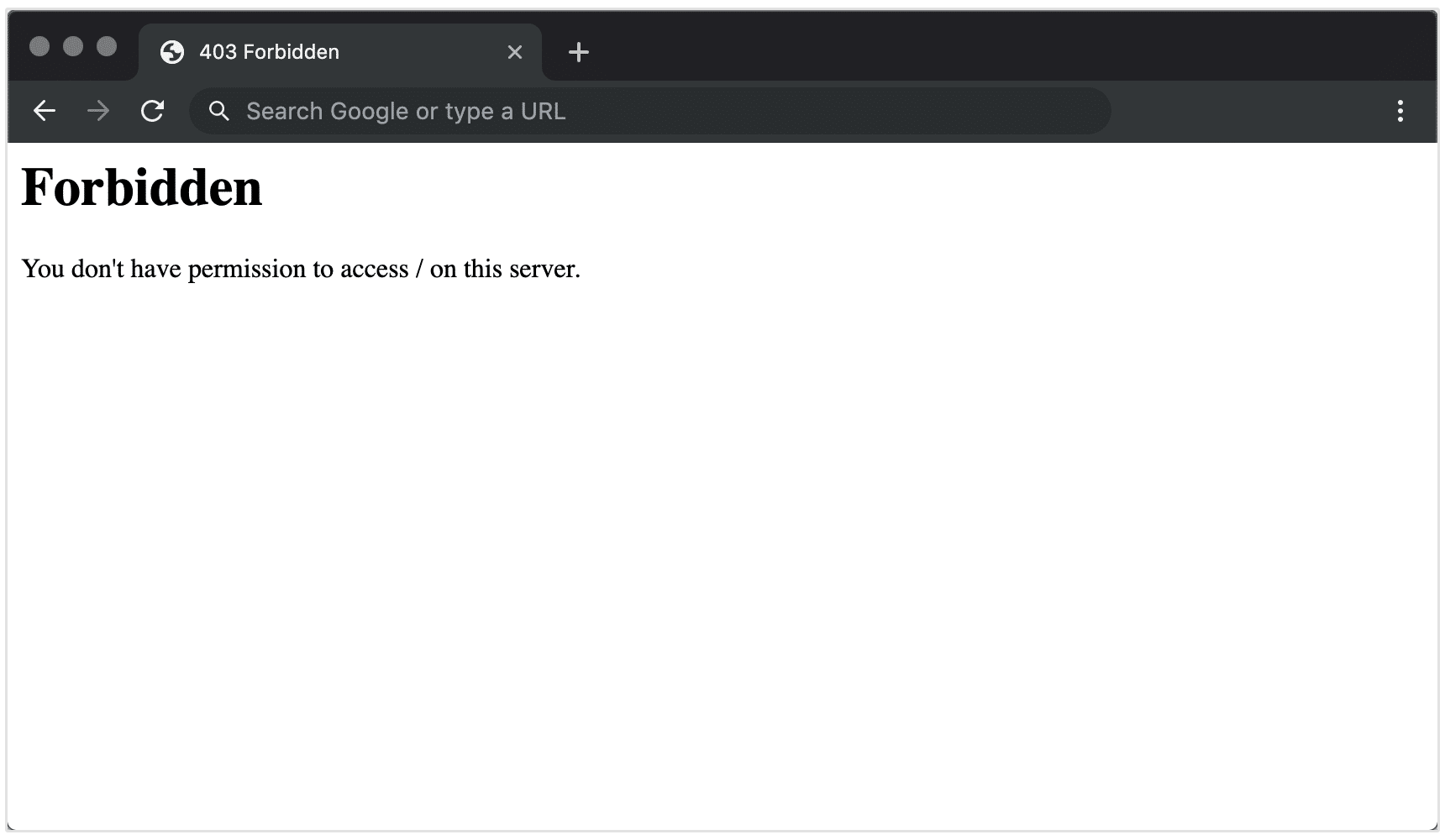
Der Statuscode 403 zeigt an, dass der Server die Anfrage des Clients versteht, aber die Erlaubnis dafür verweigert. Die Authentifizierungsdaten des Benutzers könnten gültig sein, dennoch verweigert der Server den Zugriff auf die Ressource.
Der HTTP 403-Fehler wird aus folgenden Gründen zurückgegeben:
Unzureichende Berechtigungen
Der Benutzer wird erfolgreich mit den bereitgestellten Anmeldeinformationen authentifiziert. Allerdings kann der Benutzer die gewünschten Dateien oder URLs nicht "lesen", "schreiben" oder "ausführen".
IP-Adresse blockiert
Wenn die IP-Adresse des Benutzers eine schlechte "Historie" von früheren Benutzern "erbt", könnte der Server die IP-Adresse blockieren.
Es könnte auch aufgrund zu vieler falscher Anmeldeversuche passieren.
Was auch immer der Grund ist, wenn die IP-Adresse blockiert wird, gibt der Server einen HTTP 403 Antwortcode zurück.
Anfrage durch Sicherheitseinstellungen blockiert
Die Anfrage wird durch Sicherheitseinstellungen blockiert, wie zum Beispiel "Firewall-Regeln".
Geo-Standortbeschränkungen
Benutzer können aufgrund falscher CDN-Fehlkonfigurationen nicht auf den Inhalt basierend auf ihrem Standort zugreifen. Es könnte auch aufgrund von "Firewall-Regeln", "IP-Blockierung" oder regionenspezifischen "Lizenzvereinbarungen" passieren.
Einschränkungen der Access Control List (ACL)
Der Server blockiert den Zugriff basierend auf Berechtigungslisten. Diese Listen bestimmen, welche Personen oder Gruppen die Ressource "erlaubt" oder "verboten" nutzen dürfen.
Ungültiges oder fehlendes SSL/TLS-Zertifikat
Der Zugriff ist eingeschränkt, weil der Benutzer versucht, eine Verbindung zum Server ohne ein gültiges SSL/TLS-Zertifikat herzustellen.
Ressource ausdrücklich verboten
Der Server ist so konfiguriert, den Zugriff auf die angeforderte Ressource ausdrücklich zu "verbieten".
Gesperrter Benutzeragent
Die Anfrage wird abgelehnt, weil der Server den Browser oder Bot des Benutzers blockiert.
Verzeichnisauflistung verweigert
Der Server ist so eingestellt, dass die "Verzeichnisauflistung" verhindert wird. Der Benutzer versucht, auf ein Verzeichnis zuzugreifen, dem eine "Indexdatei" fehlt.
Datei- oder Verzeichnisberechtigungen
Der Server hat Berechtigungen festgelegt, um den Zugriff zu beschränken, wodurch der Benutzer daran gehindert wird, die Ressource zu erreichen.
Beschränkungen der Referrer-Policy
Die Anfrage wird blockiert, weil sie von einer nicht erlaubten Referrer-URL stammt.
Ratenbegrenzung oder Kontingente
Der Benutzer hat die Zugangsquoten oder Ratenbeschränkungen überschritten, die vom Server auferlegt wurden, was zu einer Ablehnung weiterer Anfragen führt.
Authentifizierung erforderlich, aber nicht bereitgestellt
Der Zugriff auf die Ressource ist eingeschränkt, weil der Server eine Authentifizierung erwartet, die der Benutzer nicht bereitgestellt hat.
Die Antwort des Servers auf einen 403-Fehler enthält keinen WWW-Authenticate-Header, da die Authentifizierung nicht das Problem ist. Stattdessen zeigt sie an, dass der Server die Anfrage versteht, aber ausdrücklich den Zugriff verweigert.
Wenn der 403-Status zurückgegeben wird, wird die Angabe anderer Anmeldeinformationen das Problem nicht lösen. Der Client muss die entsprechenden Berechtigungen erhalten, um auf die Ressource zuzugreifen.
Was ist der Unterschied zwischen "verboten" und "nicht autorisiert"?
Beide Begriffe "Verboten" und "Nicht autorisiert" stellen unterschiedliche Arten von Zugriffsproblemen in HTTP-Antworten dar.
Lassen Sie uns die Unterschiede zwischen "Forbidden" und "Unauthorized" herausfinden.
Ein 401 ist ein Client-seitiger Fehler, der anzeigt, dass die Anfrage keine gültigen Authentifizierungsdaten enthält und der Benutzer ‘[nicht] autorisiert’ ist, auf den Server zuzugreifen. Daher wird die Fehlerseite geladen.
Um dies zu lösen, muss der Client gültige Authentifizierungsdaten bereitstellen, wie im WWW-Authenticate-Header in der Antwort des Servers angegeben.
Umgekehrt zeigt ein 403-Fehler an, dass der Server die Anfrage versteht, aber den Zugriff verweigert, selbst wenn die Anmeldedaten korrekt sind. Daher bleibt in diesem Fall der Zugriff auf die Ressource ‘verboten.’
Dies tritt auf, wenn der Client authentifiziert ist, aber die notwendigen Berechtigungen und Privilegien fehlen. Der Client kann die Ressource ohne die entsprechenden Berechtigungen nicht abrufen, und die Verwendung anderer Anmeldeinformationen wird das Problem nicht lösen.
Wie wirken sich 401- und 403-Fehlercodes auf Ihr SEO aus
401- und 403-Fehlercodes können sich in mehrfacher Hinsicht negativ auf Ihr SEO auswirken:
Frustrierende Benutzererfahrung
Das Auftreten von 401- oder 403-Antwortcodes kann für Benutzer frustrierend sein. Diese HTTP-Fehler treten häufig auf, wenn sie versuchen, auf Inhalte zuzugreifen, von denen sie glauben, dass sie die Berechtigung haben, sie anzusehen.
Diese unerwartete Barriere kann zu Verwirrung und Unzufriedenheit führen und den Fluss ihrer Interaktion mit Ihrer Seite unterbrechen.
Das Ergebnis ist nicht nur eine sofortige Störung; diese Fehler können die Absprungraten erheblich erhöhen, da Benutzer die Seite möglicherweise sofort verlassen, um nach einer zugänglicheren Alternative zu suchen.
Im Laufe der Zeit kann dies die wichtigsten Metriken der Benutzerinteraktion negativ beeinflussen, einschließlich "Sitzungsdauer", "Seitenbesuche" und "Konversionsraten", was letztendlich die gesamte Benutzererfahrung und die Effektivität der Website bei der Erreichung ihrer Ziele beeinträchtigt.
Störung der internen Verlinkung und [Site]-Struktur
Interne Links zu Seiten, die entweder einen 401 Unauthorized oder 403 Forbidden Fehler zurückgeben, werden keinen "Linkwert" weitergeben.
Es wird die Erstellung einer ordnungsgemäßen "Site-Architektur" stören, was zu einer schlechten "Besucher-Erfahrung" führt.
Zu viele URLs auf Ihrer Domain zu haben und diese HTTP-Fehlercodes "zurückzuziehen", wirkt sich negativ auf die "SEO"-Gesamtbewertung Ihrer Website aus.
Wenn die "Linkautorität" schwächer wird, sinkt das organische "Ranking" Ihrer Website. Dies führt zu reduziertem organischen "Traffic" und weniger "Conversions".
Daher ist es egal, ob Ihr Server einen 401 oder 403 zurückgibt; beide sind schädlich für die SEO Ihrer Website.
Reduzierung der Indexierung und Suchsichtbarkeit
Suchmaschinen indexieren keine Seiten, die "Ungültige Anmeldeinformationen" oder "Zugriff verboten" Probleme zurückgeben.
Daher werden sie nicht in den Suchergebnissen erscheinen. Dies kann die Sichtbarkeit der Website einschränken und den organischen Suchverkehr reduzieren.
Darüber hinaus kann das Blockieren des Zugriffs auf wichtige oder wertvolle Inhalte die Fähigkeit der Website beeinträchtigen, gut für relevante Suchanfragen zu ranken.
Gibt es irgendwelche [Ähnlichkeiten] zwischen 401 vs. 403 [Fehlercodes]?
Ja, hier sind die Hauptähnlichkeiten zwischen den 401- und 403-Codes:
Zugriff verweigert
Sowohl die Fehlercodes 401 als auch 403 zeigen an, dass der Zugriff auf eine Ressource "verweigert" wird. Das bedeutet, dass der Server sich weigert, dem Client den angeforderten Inhalt bereitzustellen. In beiden Fällen kann der Client die Ressource nicht wie vorgesehen anzeigen oder damit interagieren.
Diese beiden Fehlercodes sind Teil des HTTP-Protokolls und werden von Webservern und Clients weithin erkannt, um auf spezifische Zugriffsprobleme hinzuweisen.
Auswirkungen auf das Crawlen von Suchmaschinen
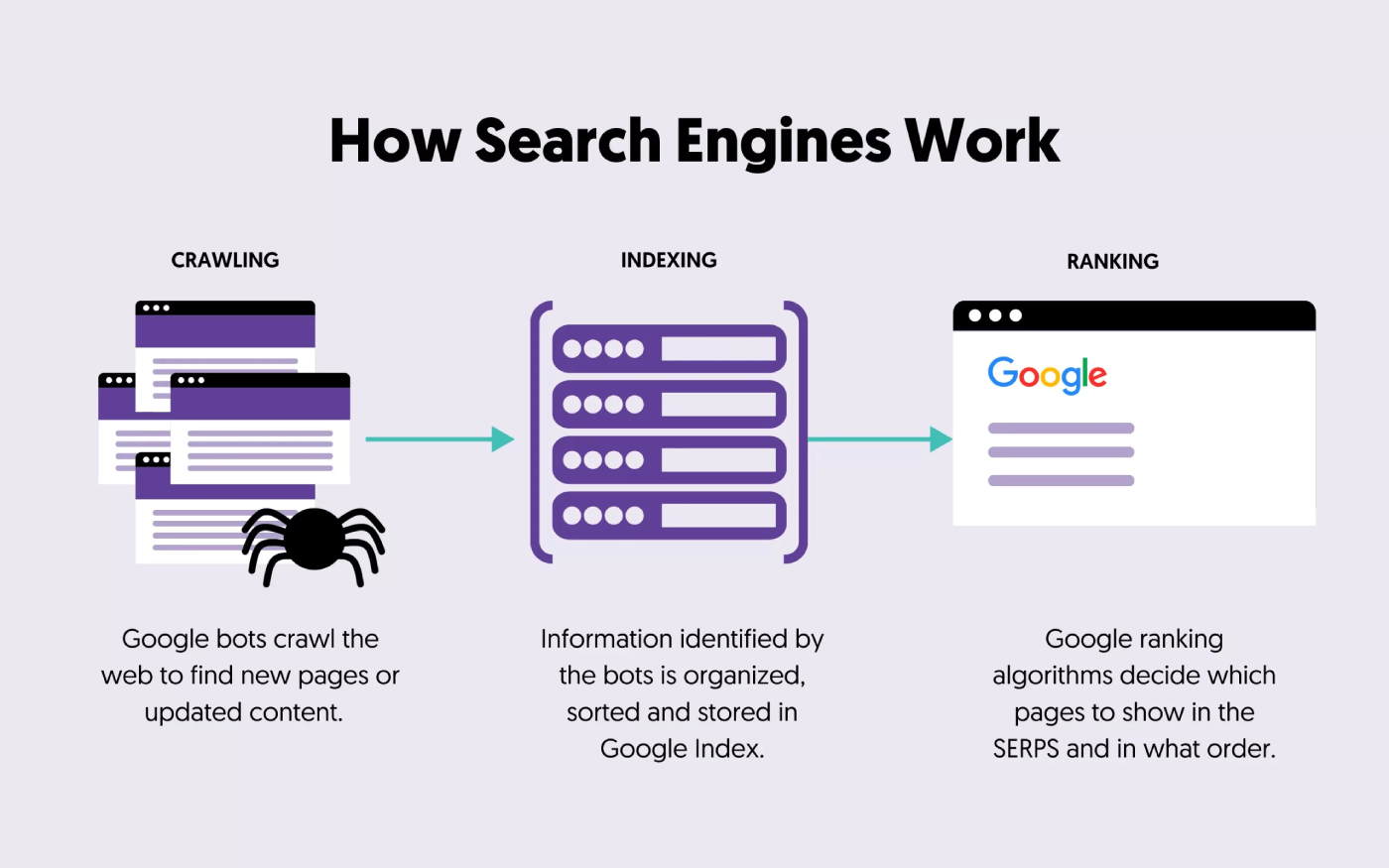
Sowohl HTTP 401- als auch 403-Fehler verhindern, dass Googlebots und andere Webcrawler auf die betroffenen Seiten zugreifen und diese indexieren.
Wenn eine Suchmaschine auf diese Fehler stößt, wird sie die betroffenen Seiten nicht in ihren Index aufnehmen. Daher führt es zu reduziertem organischem Suchverkehr.
Reaktionsverhalten
Sowohl 401 "Unauthorized" als auch 403 "Forbidden" Fehler zeigen an, dass weitere Maßnahmen vom Client erforderlich sind. Allerdings unterscheidet sich die Art dieser Maßnahmen.
Für einen 401-Fehler müssen gültige Authentifizierungsdaten bereitgestellt werden. Für einen 403-Fehler müssen entsprechende Berechtigungen oder Zugriffsrechte [erhalten] werden.
Fehlerbehandlung und Benutzererfahrung
Sowohl "401" als auch "403" Fehler führen zu Benutzerfrustration. Seitenbesucher sehen Meldungen, die darauf hinweisen, dass sie nicht auf den Inhalt zugreifen können, was die Benutzerzufriedenheit beeinträchtigen und die Absprungraten erhöhen kann.
Beide "Fehler" können zu einer schlechten "Benutzererfahrung" führen, wenn "Benutzer" nicht auf den gewünschten "Inhalt" oder die gewünschte "Funktionalität" zugreifen können.
Sicherheit
Beide Statuscodes sind unerlässlich für den Schutz von Webressourcen. Sie stellen sicher, dass nur verifizierte Konten auf "sensitive data" zugreifen können.
Dies hilft, die "Authentizität" und "Privatsphäre" der [Informationen] zu wahren. Durch die Einschränkung des Zugriffs verhindern diese [Codes], dass unbefugte [Benutzer] private [Inhalte] einsehen oder ändern.
Sie bieten auch eine zusätzliche "Schutzschicht" gegen potenzielle "Sicherheitsverletzungen".
Wie man 401- und 403-Fehlercodes "identifiziert"?
Es gibt mehrere Möglichkeiten, die Fehlercodes 401 und 403 zu identifizieren:
Verwenden Sie die Google Search Console
Google Search Console kann helfen, "401" und "403" [Probleme] zu identifizieren.
Melden Sie sich bei der Google Search Console an und gehen Sie zum "Indexierung"-Abschnitt.
Klicken Sie nun auf “Seiten”, um Fehler im Zusammenhang mit zu finden:
- Blockiert aufgrund einer "nicht autorisierten Anfrage" (401) oder
- Blockiert aufgrund von "Zugriff verboten" (403)
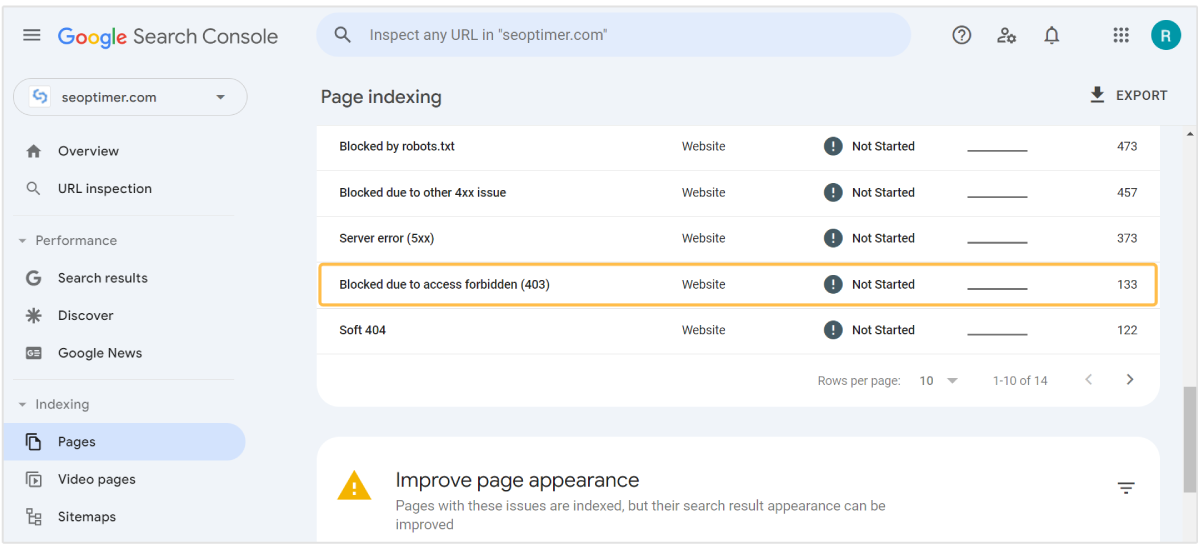
Nach dem Klicken auf den Grund (Fehler) Namen finden Sie eine vollständige Liste der URLs, die dieses Problem haben. Sie können diese Liste exportieren und geeignete Maßnahmen ergreifen, um sie zu beheben.
Nutzen Sie die Hilfe des SEOptimer URL-Statuscode-Prüfers
Sie können auch den URL-Statuscode-Checker von SEOptimer verwenden, um den "Statuscode" auf einer Seite zu bewerten.
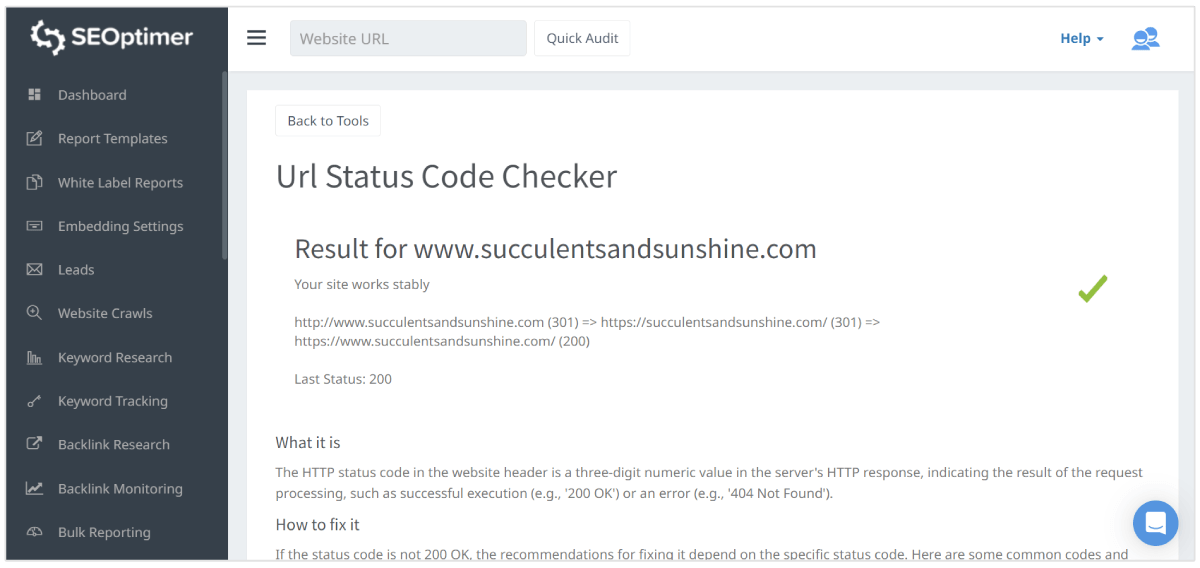
Das Tool wird überprüfen, ob der Statuscode 200 ist. Wenn er es nicht ist, wird es auch feststellen, ob die Antwort "Verweigert" (403) oder "Nicht erlaubt" (401) ist.
Überprüfen Sie den WWW-Authenticate-Header
Öffnen Sie die Entwicklerwerkzeuge in Ihrem Browser, indem Sie mit der rechten Maustaste auf die Seite klicken und "Untersuchen" auswählen oder F12 drücken.
Wechseln Sie zur "Netzwerk"-Registerkarte und aktualisieren Sie die Seite, um alle HTTP-Anfragen zu erfassen.
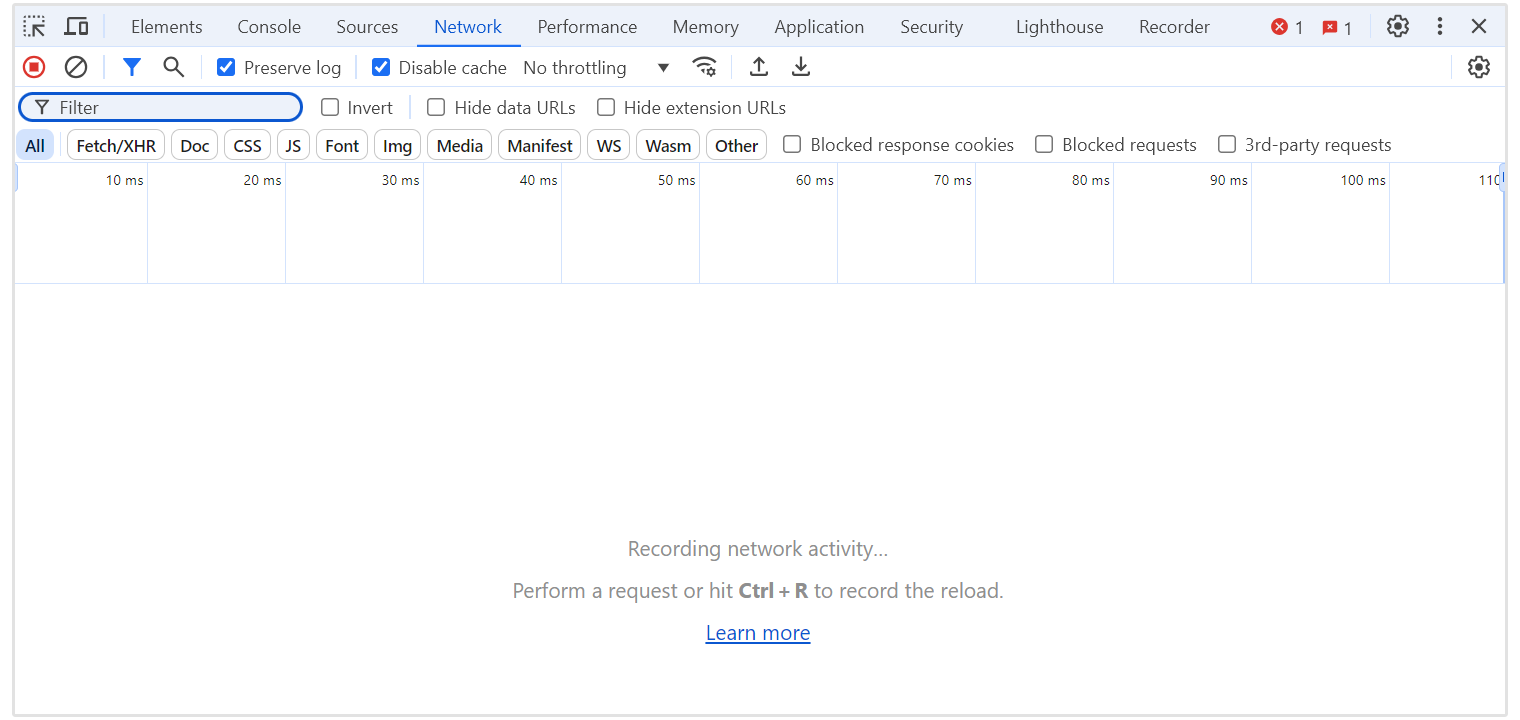
Suchen Sie nach der Anfrage, die zu einem 401- oder 403-Statuscode führte, und klicken Sie dann darauf, um die Details anzuzeigen.
Im "Headers"-Tab scrollen Sie durch den "Response Headers"-Abschnitt, um den WWW-Authenticate-Header zu finden.
Diese Überschrift wird Details über die Authentifizierungsmethode bereitstellen, die der Server erfordert, und Ihnen helfen zu verstehen, warum der Zugriff verweigert wurde und welche Schritte erforderlich sind, um den Fehler zu beheben.
Fazit
Denken Sie daran, dass sowohl 401- als auch 403-Fehler Ihnen unterschiedliche Dinge sagen.
Eine 401 [Nicht autorisiert] Antwort teilt Ihnen mit, dass der Server den Benutzer nicht erkennen kann, weil die [Details] ungültig sind.
Ein 403-Fehlercode "Verboten" deutet darauf hin, dass der Server die Anfrage verstanden hat. Allerdings konnte er sie aufgrund [unzureichender] Berechtigung nicht verarbeiten.
Es hat keinen Sinn, sich erneut anzumelden, da der "Fehler" weiterhin auftreten wird, solange die [Benutzerberechtigung] nicht aktualisiert wird.
Das Verständnis des Unterschieds zwischen dem Statuscode 401 und 403 kann es einfacher machen, Zugriffsprobleme zu lösen und Ihre Website reibungslos für alle laufen zu lassen.